In a modern city environment there are many dangers that can unexpectedly break service availability. Commonly it is an excavator breaking a critical cable, or critical equipment failing in the server room. Kiuru MSSP geo-redundancy aims to mitigate these dangers.
What Do We Need
We need only two things:
- Service continuity: when a user needs the service, it is available.
- Easy recovery: when a disaster occurs, service recovery is quick and painless.
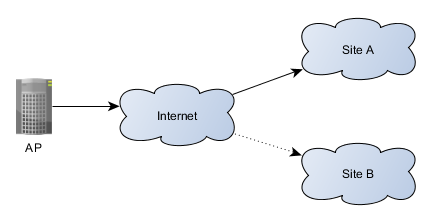
We need a geographically redundant (geo-redundant) solution that replicates key MSSP system data to a secondary site allowing service continuity in case the primary site becomes unavailable.
Design Decisions
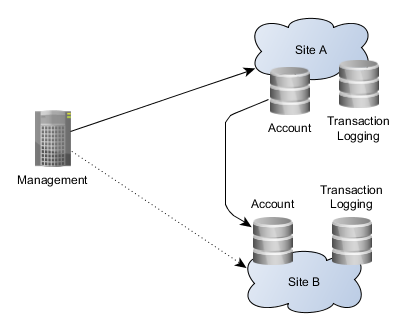
- All service requests go only to the primary site, until the secondary site is taken into use. Secondary site maintains all account data all the time, but receives no service requests during normal system operations. This makes it possible to take the secondary site on-line (to service signature traffic) instantly if the primary site fails.
- The MSSP system database has two kinds of data:
- Account data that changes rarely.
- Transaction and log data which change all the time at a high rate.
Only account data is replicated to the secondary site. This reduces the volume of the data needed to synchronize between the sites significantly, while introducing only a negligible loss of service when the primary site fails. Only the currently ongoing signature transactions are lost, while all new signature requests are served correctly at the secondary site.
- The MSSP system is monitored for liveliness. If the monitoring system notices that the primary site is not healthy according to the metrics, it can direct signature traffic to the secondary site instantly and automatically without human intervention. This minimizes the time when the service is not available to the users.
- After the problem at the primary site has been fixed, the MSSP system has tools which allow account data changes done at the secondary site to be synchronized back to the primary site. This is not automatic because switching data and traffic from secondary site to the primary site is always manual, thus preventing automatic flip-flopping between the sites.
Implementation
In our approach there are four rules to the geo-redundancy data replication:
- Insert/Update/Delete statements are replicated.
- SQL statements do not use side-effects to do their task and possibly producing different data row at replica than at the master. (Like explicit SEQUENCE referrals in the INSERT SQL statements, or using DEFAULTs of sequences, or triggers using sequences, or ….)
- Inserts/Updates must use unique and non-conflicting indexes, and updates must never cause conflicts unless some previous operation is left out.
- Only SQL transactions with successful commit are replicated, SQL transactions with errors are thrown away.
Service Continuity
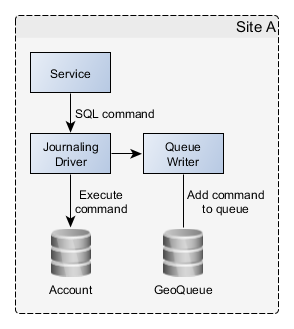
This is accomplished with a custom JDBC Journaling Driver which is plugged in between the MSSP application server’s JDBC calls and the actual database driver:
The secondary site pulls operations from primary site’s GeoQueue and executes them in its own database:
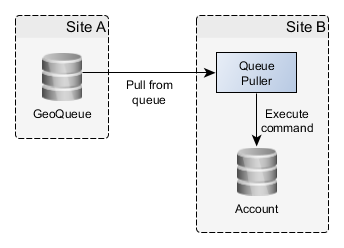
After execution, the secondary site removes the executed operations from the GeoQueue and records them into a log (not depicted above) with execution status for error analysis.
Recovery
Manual recovery is done with command line tools. One command is used for checking if the GeoQueue contains something to replicate. Another tool is used for the actual replication.
Additionally the geo-redundancy command line tools contain a database comparator which can be used to verify that primary and secondary are consistent. Detection and repair of non-consistency before a user detects it is highly valuable.